callback机制是为了提高代码可重用性的。一般是会把两个项目之间相同的部分写成一个env,把不同的地方通过callback函数来实现。
callback机制简单理解
一般callback机制指的是在进行某个主体任务之前对任务执行的过程通过Callback函数对其进行修饰,或之后对任务执行的结果进行修饰。如uvm里面自带的post_randomize、pre_body函数就是一种广义的callback机制函数。
那么如果需要在driver进行sequence传递之前实现一个pre_trans的callback函数,需要怎么做到呢?分为两种情况,写VIP和调用VIP
- 自己写的VIP:需要首先定义一个callback类A继承于uvm_callback, 然后使用typedef定义一个A_pool. 最后在driver里面注册类A, 然后在执行的地方对类A进行调用。
- 调用VIP:直接声明一个继承于已有的callback函数A的类my_callback, 并通过工厂机制注册这个callback类, 然后在testcase里面的connect_phase里面对callback类进行实例化,并将其加入到A_pool里面。然后在使用的地方只需要使用`uvm_do_callbacks(my_driver, A, pretran(this, req))就可以了。这里的A只是callback类的接口骨架,真正的实现在my_callback类里面。
TLM通信
端口主要有put, get, peek, analysis, transport类型, 一般是同类型的端口连接同类型的端口.
put, get, peek, transport类型的端口有阻塞型, 非阻塞型, 即可阻塞又可非阻塞的类型. nonblocking_peek_export()
analysis端口没有阻塞和非阻塞区分, 因为analysis端口是以广播的形式发送数据, 不会等到接收方回复就会发送下一个数据.
- put端口用于发送数据, get端口用于接收数据, transport端口既可以发送也可以接收数据.
- port类型的端口A表示控制方, export的端口B表示接收方, 只能由控制方来A发起信息传输过程.
- peek类型的端口在接收数据后并不好从fifo中取出数据, 只读取数据.
一般一个端口都是声明为: blocking_get_export, blocking_put_port这种形式.然后一般是在模块的包裹层进行两个模块的TLM信号传输连接. 如env层进行model > scrb, 或者mnt > fifo > scrb.
UVM sequence机制的简单了解
sequence机制的出现是为了将driver里面产生激励的过程剥离出来处理。其中里面涉及到的知识点主要有:
- sequence里面用到的uvm_do, uvm_do_on等产生激励的宏的使用。(sequence,sequencer的声明)
- sequence怎么与sequencer连接起来,sequencer怎么将信号送入到driver里面?(sequence与sequencer的连接sequencer与driver的连接)
- virtual sequence的出现是为了解决什么问题?如何使用?(virtual sequence的声明与调用。)
- sequence和sequencer的声明
sequence的声明
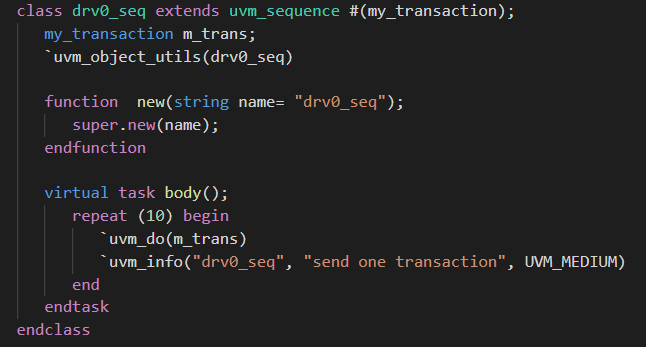 sequencer的声明
sequencer的声明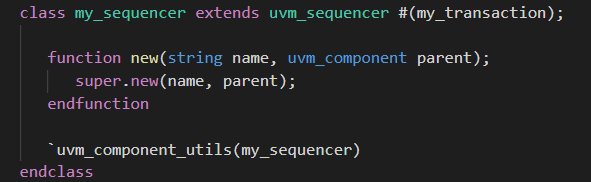
- sequence里面uvm_do, uvm_do_on, uvm_do_with的使用
- uvm_do是一般用在不是使用virtual sequence的情况下。默认就是sequence启动时为其指定的sequencer.
- uvm_do_on可以显示的指定使用那个sequencer发送此transaction. 一般是用在使用virtual sequencer的情形中。
- uvm_do_with可以在生成激励的时候传入约束
- 验证体系下,sequence与sequencer之 间的连接,配置。
- 在testcase里面进行配置,使用uvm_config_db.

- 在testcase里面进行配置,使用uvm_config_db.
- sequencer与driver之间的通信
- 通过TLM来进行通信,在agent里面的connect_phase里面对他们进行连接。
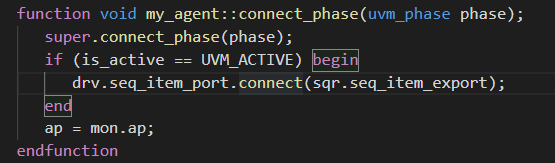
- 通过TLM来进行通信,在agent里面的connect_phase里面对他们进行连接。
- virtual sequence的出现是为了解决什么问题,如何声明和配置virtual sequence?
- virtual sequence的出现主要是为了解决sequence之间协同给激励的情况。方便知道什么时候给什么激励。
- 首先需要声明一个virtual sequence, 和一个 virtual sequencer.
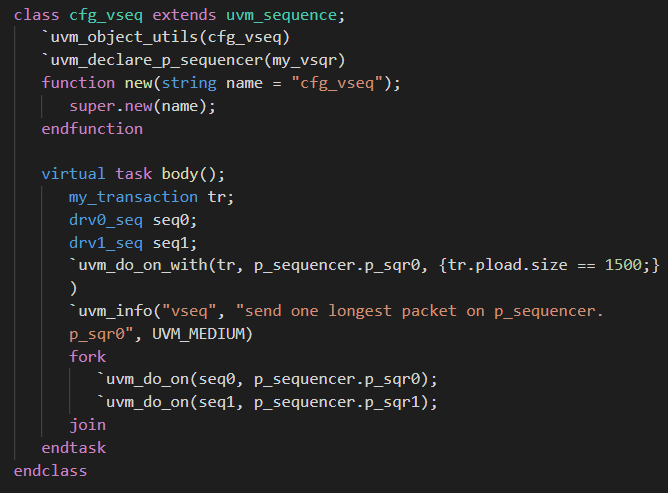
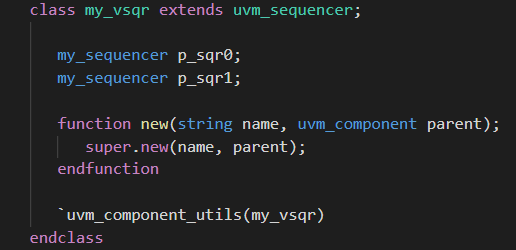
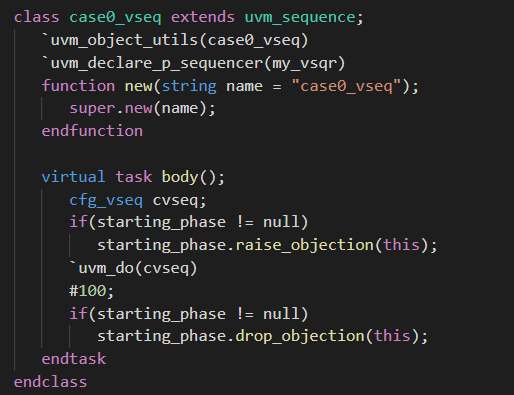
- 然后还需要声明一个调用virtual sequence的case0_vseq.
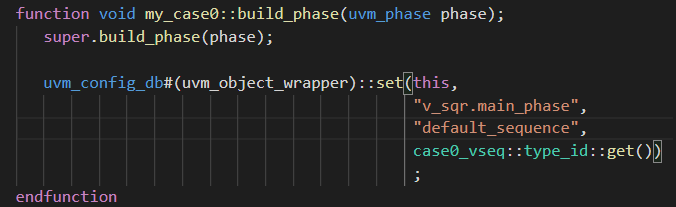
- 最后再在testcase里面的build_phase通过uvm_config_db对他们进行连接
- sequence和sequencer的声明
sequence的声明
UVM寄存器模型简单理解
寄存器模型对DUT寄存器进行读写操作的数据流动
寄存器模型是对真实寄存器进行的一个软件环境下的建模。通过对寄存器模型进行配置可以完整的实现DUT里面寄存器的功能。
RAL的意思是寄存器抽象层(register abstraction layer)
寄存器模型一般是根据DUT的寄存器spec来自动生成的(一般会有一个xml文件)。
创建寄存器模型主要涉及的类有: uvm_reg_filed, uvm_reg, uvm_reg_block, uvm_reg_map
这四种类所涵盖的大小从左往右越来越大。
uvm_reg是把uvm_reg_field包裹起来的
uvm_reg_block是把uvm_reg包裹起来的
uvm_reg_block包裹uvm_reg_map, uvm_reg_map包裹uvm_reg. 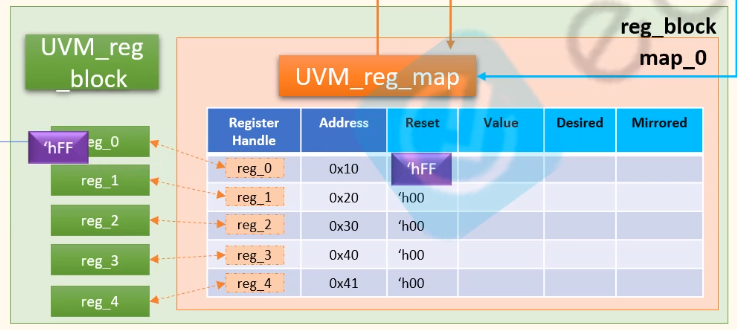
寄存器模型(uvm_reg)进行操作的方法主要有: reset(), set(), write(), read(), updata()等10种。在uvm_reg_map里面包含reset值,desired值,mirror的值。而对应的寄存器模型(uvm_reg)方法都是对这几种值进行处理。其中read, write, updata会涉及到与dut的交流,如uvm_block.reg_2.read()就是根据reg_2的地址直接读取这个寄存器上面的值;而其他的7种方法都只是停留在寄存器模型内部的访问,如uvm_block.reg_2.get()就是返回reg_2所对应的mirror value。
而执行write(), read(), updata()的时候会涉及到对DUT的前门访问还是后门访问。(可以在进行方法调用的时候进行指定) 其中前门访问指的是通过总线接口进行访问。 后门访问指的是通过RTL路径进行访问。
前门访问消耗仿真时间,后门访问容易出错。
其实通过寄存器模型对DUT进行操作,跟使用普通的sequence进行操作是类似的。需要把寄存器模型的操作使用一个uvm_sequence类包裹起来,然后通过config_db将其与sequencer连接起来,然后通过driver送到dut中。这里其实是先进行寄存器配置,然后再通过sequence传递数据
本文原创,错误之处在所难免!盼指出!